
Historie
Contents
2. Historie#
Die Entwicklung von Datenbanksystemen geht ca. 100 Jahre zurück. Dieses Kapitel hat nicht den Anspruch die Historie in ihrer Gesamtheit vollständig zusammenzufassen. Wir werden lediglich auf bestimmte zeitliche Epochen kurz eingehen, um die Relevanz von Datenbanksysteme und ihren Ursprung besser zu verstehen. Eine gute Übersicht für die verschiedenen Etappen der modernen Datenbankentwicklung bietet, die von Felix Naumann erstellte RDBMS-Geneology-Übersicht, die unten abgebildet ist.
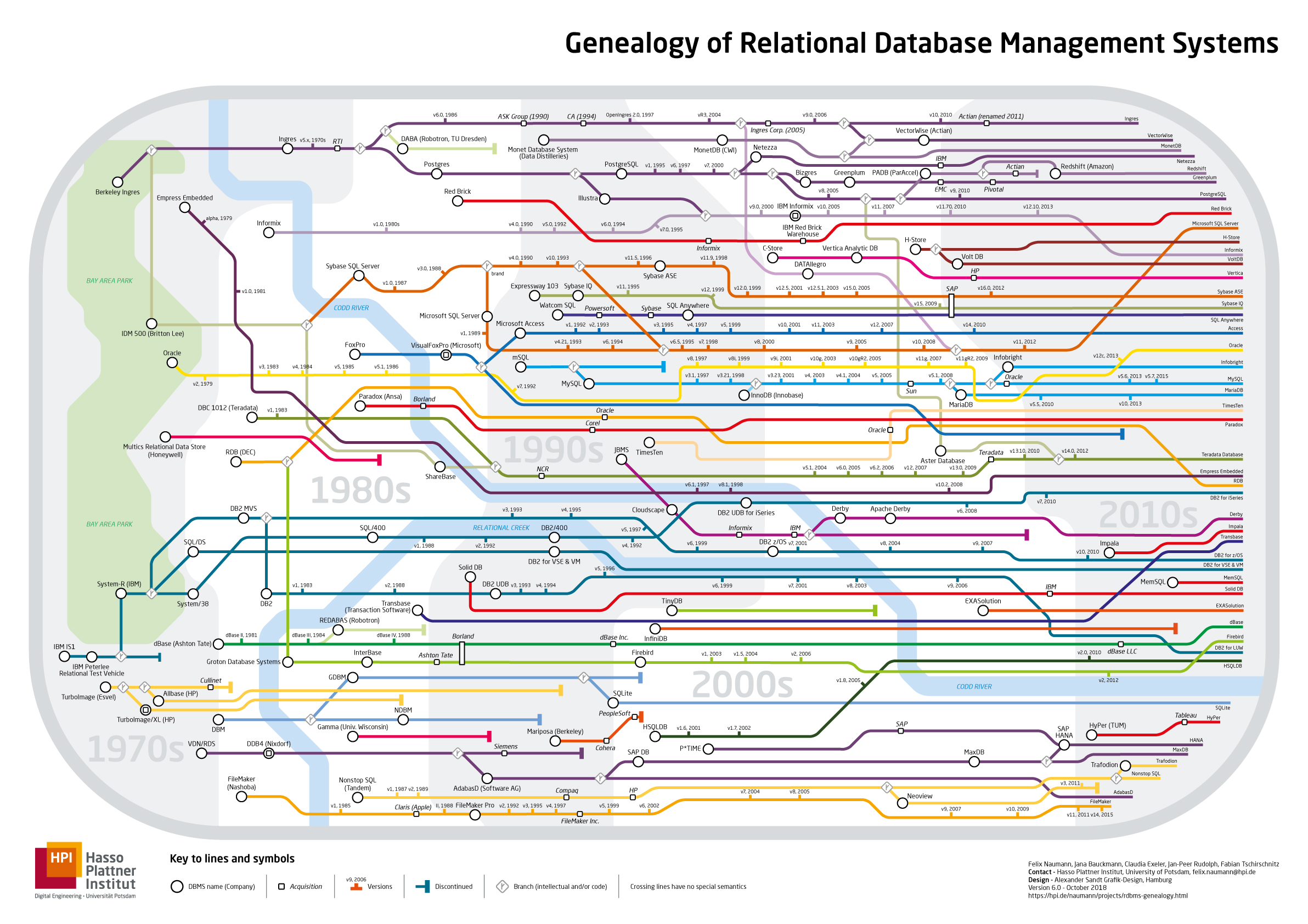
Wie man in dieser Übersicht sehen kann, entstanden die ersten modernen Datenbanksysteme in den 70ern und bis heute werden an neuen Systemen zum effizienteren Umgang mit großen Datenmengen und neuen Datenmodellen geforscht. Um diese Datei besser sichten zu können folgen Sie dem Link zu der hochauflösbaren PDF-Datei.
2.1. Frühe automatisierte Speichertechnologie#
Bei der Entwicklung von Datenbanksystemen war ein Unternehmen besonders aktiv. Herman Hollerith gründete bereits 1896 die Tabulating Machine Company, die 1924 in International Business Machines Corporation (IBM) umbenannt wurde. In Ihrem Ursprung entwickelte IBM Lochkartensysteme, die Informationen durch physische Löscher auf Karten, abspeichern und ablesen konnten.

Herman Hollerith

Lochkarte

Lochkartenleser Bei der Volkszählung in 1890 wurden über 40 solcher Maschinen zum Lesen und Stanzen von Lochkarten eingesetzt. Lochkartensysteme wurden bis in die 60er Jahre als Speichermedien benutzt bis sie dann von Magnetbändern abgelöst werden konnten.
2.2. 1960er Jahre#
In den 60er Jahren wurden mit der Entwicklung von neuen Speichermedien neue DBS entwickelt, die durch Zeigerstrukturen navigierende Datenmanipulation erlaubten. Es war auch möglich Daten hinsichtlich ihrer konzeptionellen und internen Darstellung zu abstrahieren. Zu diesen Abstraktionsebenen werden wir im nächsten Kapitel mehr erfahren. Die ersten Systeme dieser Art waren anwendungsspezifisch und geräteabhängig. Redundanz und Inkonsistenz von Daten konnte man nicht sinnvoll kontrollieren.
2.3. 1970er bis 1980er Jahre#
In den 70er Jahren gab es die ersten fundamentalen Theorien zu Relationalen Datenbanksystemen, die die sinnvolle Darstellung von Daten in Tabellenstrukturen erklärten. Zudem wurde das 3-Ebenen-Konzept für die Abstraktion von Datenspeicherung vorgestellt und der Bedarf an deklarativen Anfragesprachen erörtert. Es entstanden die ersten geräte- und datenunabhängigen Datenbanksysteme, die anhand des relationalen Modells von Codd Redundanzfreiheit und Konsistenz ermöglichen konnten. Die parallelen Entwicklungsstränge befanden sich bei IBM mit System R, UC Berkeley mit Ingres, und Oracle
1970: Ted Codd (IBM): Relationenmodell als konzeptionelle Grundlage relationaler DBS
1974: System R (IBM): Erster Prototyp eines RDBMS
ca. 80.000 LOC (PL/1, PL/S, Assembler), ca. 1,2 MB Codegröße
Anfragesprache SEQUEL (≠ SQL)
erste Installation 1977
1975: Ingres (University of California at Berkeley)
Anfragesprache QUEL
Vorgänger von Postgres, Sybase, …
1979: Oracle Version 2
2.4. 1980er bis 1990er Jahre#
In den 80er und 90er Jahren wurden die Entwicklung und Forschung fortwährend fortgesetzt. Datenmengen wurden größer, es gab neue Speichermedien, wie Magnetdisks, CDs, und Festplatten. Zu textuellen Daten kamen mehr komplexe Datenobjekte hinzu. Um die Verarbeitung der Datenmengen zu gewährleisten gab es auch die ersten Ansätze zur parallelen Datenverarbeitung. Gleichzeitig konnten die Systeme plattformunabhängig auch auf kleinen Rechnern installiert werden.
2.5. 2000er Jahre#
In den 2000er Jahren und mit der Verbreitung vom Internet gab es weitere Entwicklungen zur Verarbeitung von neuen Datenarten, wie zum Beispiel multimodale Objekte und semi-strukturierte Daten. Gleichzeitig gab es neue Programmierparadigma für verteilte Datenverarbeitung, die auch durch die neuen großen Webunternehmen gefördert wurden. Dies heizte auch die Forschung im Bereich paralleler Datenbanksysteme weiter an. Auch von Interesse waren nunmehr integrierte Systeme, bei denen heterogäne Datenbanksysteme anhand von Mediatoren oder in Föderationen benutzt werden konnten. Gleichzeitig konnte mit den neuen Trends im Bereich von Mobile Computing an entsprechenden Systemen für Kleinstgeräte geforscht werden.
2.6. 2010er bis heute#
In 2010 und später ist die Verarbeitung von Terabytes von Daten keine fundamentale Herausforderung mehr. Web-scale Datamanagement ist Stand der Technik großer Internetriesen, wie Google, Facebook und Twitter.
Mit den neuen Trends im Bereich des Big Data und den Erwartungen an maschinelles Lernen, wuchs der Markt für sogenannte “Systems for ML” und “Data lake management”. Mehr dazu in den Mastervorlesungen.
Ein weiterer Forschungsstrang bot neue Entwicklungen aus dem Bereich der Hardware: FPGA, GPGPU, SSD, Main-Memory, Infiniband, die Annahmen über Speicherhierarchien und Kostenmodelle verändern würden.